Making Spoken Dialogue Models See the Face
An explicit turn-taking objective unlocks visual turn cues that next-token audio prediction ignores音声対話モデルに顔を「見せる」
明示的なターンテイキング目的関数が、next-token 音声予測では無視される視覚的ターン交代手がかりを引き出す
Anonymous authors — under review匿名著者 — 査読中
Paper, arXiv & code: coming soon論文・arXiv・コード: 準備中
A spoken dialogue model that watches its partner's face —
and sees turn changes coming ~1 second early
(ROC-AUC 0.905 with the face vs 0.810 without).対話相手の顔を見ながら話す音声対話モデル —
話者交代を約 1 秒前に予見する
(顔あり ROC-AUC 0.905 vs 顔なし 0.810)。
One real hand-off, two predictions. Left: the speaker's face, drawn from the
61 coefficients the model actually sees. Right: the model's running prediction that
the turn is about to be handed over — green
watching the face, gray with the face hidden.
Only the green curve rises before the red hand-off line. 🔊 Unmute for the dialogue.
1 つの実際の話者交代、2 つの予測。左: モデルが実際に見ている 61 係数から
描いた話者の顔。右: 「まもなくターンが譲られる」というモデルの逐次予測 —
緑は顔を見ている時、
灰は顔を隠した時。
赤い交代線の前に立ち上がるのは緑だけ。🔊 音を出すと対話が聞こえます。
TL;DR — We feed a full-duplex spoken dialogue model (Moshi-style) a 12.5 Hz
facial-coefficient stream of its interlocutor. The face demonstrably carries
turn-taking signal, but the standard next-token audio objective ignores it
entirely. Adding one lightweight auxiliary turn-yield head makes the model use
it: +0.094 ROC-AUC on MultiDialog, replicated at +0.038 on Seamless
Interaction with an identical training budget. Cross-corpus attribution shows
head rotation is the only camera-robust facial cue — gaze and mouth
contributions flip with framing.
要約 — full-duplex 音声対話モデル(Moshi 系)に、対話相手の顔係数ストリーム
(12.5 Hz)を入力する。顔にはターンテイキングの信号が確かに含まれているが、標準的な
next-token 音声予測の目的関数はそれを完全に無視する。軽量な補助タスク
(turn-yield head)を 1 つ加えるだけでモデルは顔を使い始め、MultiDialog で
ROC-AUC +0.094、同一の学習予算の Seamless Interaction でも +0.038 と
再現された。コーパス横断の寄与分析では頭部回転だけがカメラ構図に頑健な顔手がかりであり、
視線と口の寄与は構図によって逆転する。
The three-step result3 段階の結果
1
The face carries the signal顔は信号を持っている
AUC 0.76
A simple logistic probe predicts upcoming turn-yield from 1-second windows of
raw facial coefficients alone (shuffled-label control: 0.50).単純なロジスティック回帰プローブが、生の顔係数の 1 秒窓だけから直後のターン譲渡を
予測できる(ラベルシャッフル対照: 0.50)。
2
A vanilla dialogue LM ignores it素の対話 LM はそれを無視する
Δ ≈ 0
Trained with next-token audio prediction only, zeroing the face input changes
nothing — the LM routes the face into a subspace orthogonal to its audio
predictions.next-token 音声予測のみで学習すると、顔入力をゼロにしても何も変わらない —
LM は顔を音声予測と直交する部分空間へ押し込めてしまう。
3
One auxiliary head unlocks it補助 head 1 つで解放される
+0.094 AUC
A single BCE turn-yield head (predict floor hand-over ~1 s ahead) makes the
same architecture exploit gaze, head rotation, and mouth. 95% CI [+0.089, +0.099].BCE の turn-yield head(約 1 秒先の発話権譲渡を予測)を 1 つ足すだけで、同じ
アーキテクチャが視線・頭部回転・口を活用するようになる。95% CI [+0.089, +0.099]。
Architectureアーキテクチャ
緑色の turn-yield head が本研究の介入のすべて — これが無いと顔入力はただの死荷重になる。
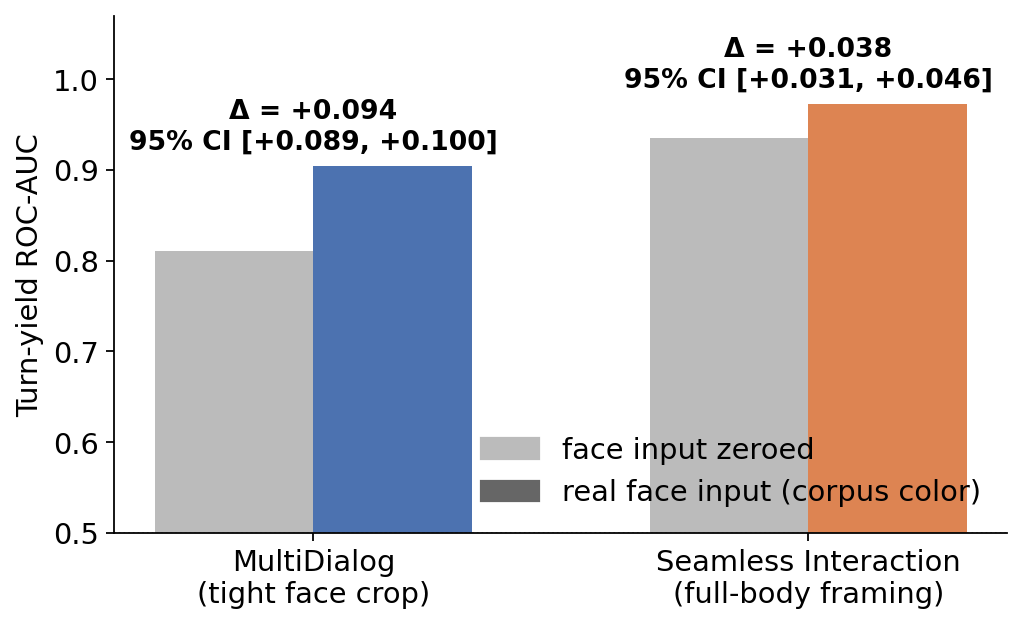
Face input improves turn prediction — on both corpora顔入力はターン予測を改善する — 両コーパスで
Turn-yield ROC-AUC of the same model with the face input present vs zeroed,
paired over identical frames. MultiDialog: 0.810 → 0.905. Seamless: 0.935 → 0.973.
Both paired-bootstrap CIs exclude zero. The Seamless margin is smaller because its
audio-only baseline is already high.
同一モデルで顔入力あり vs ゼロ化を、同一フレーム上でペア比較した turn-yield ROC-AUC。
MultiDialog: 0.810 → 0.905、Seamless: 0.935 → 0.973。どちらもペアブートストラップの
信頼区間が 0 を含まない。Seamless で差分が小さいのは、音声のみのベースラインが既に
高いため。
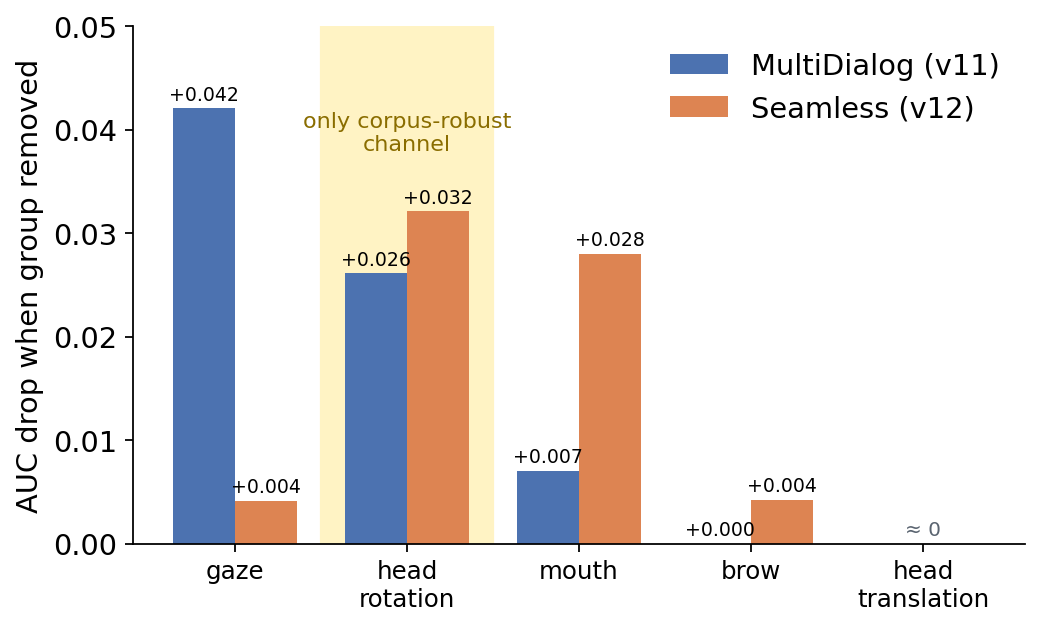
Which facial cue? It depends on the camera — except head rotationどの顔手がかりが効くか?カメラ次第 — ただし頭部回転を除いて
Leave-one-group-out attribution of the trained models. Gaze dominates under
MultiDialog's tight face crops (+0.042) but collapses under Seamless's full-body
framing (+0.004), where iris tracking degrades; mouth does the reverse. Head
rotation is the only channel that stays substantial in both (+0.026 / +0.032).
Head translation — a per-clip camera-setup constant — is structurally zeroed and
contributes nothing, by design.
学習済みモデルの leave-one-group-out 寄与分析。視線は MultiDialog のタイトな顔クロップ
では支配的(+0.042)だが、虹彩トラッキングが劣化する Seamless の全身構図では崩壊する
(+0.004)。口はその逆。頭部回転は両者で実質的な寄与を保つ唯一のチャネル
(+0.026 / +0.032)。頭部並進はクリップごとのカメラ設置定数であり、設計により構造的に
ゼロ化されていて寄与しない。
Group removed除外グループ
MultiDialog (v11)
Seamless (v12)
Reading解釈
eye / gaze視線
+0.042 (dominant)(支配的)
+0.004 (collapsed)(崩壊)
corpus-dependentコーパス依存
head rotation頭部回転
+0.026
+0.032 (largest)(最大)
robust across corporaコーパス横断で頑健
jaw / mouth口
+0.007
+0.028
corpus-dependent (reverse)コーパス依存(逆方向)
brow眉
+0.000
+0.004
noiseノイズ
head translation頭部並進
+0.000
0.000
zeroed by design設計によりゼロ化
A model trained and attributed on a single corpus would have shipped the claim
"gaze drives turn-taking." The replication shows that claim is a property of the
camera setup, not of conversation. We argue cross-corpus attribution should be the
reporting standard for multimodal dialogue cues.
単一コーパスで学習・寄与分析していたら「ターンテイキングを駆動するのは視線」という主張を
出してしまうところだった。再現実験は、その主張が会話の性質ではなくカメラ設置の性質である
ことを示している。マルチモーダル対話手がかりの報告は、コーパス横断の寄与分析を標準と
すべきだと我々は主張する。
Watch it run動作デモ
MultiDialog (v11)
Tight face crop; gaze is the leading cue.タイトな顔クロップ。視線が主要な手がかり。
Seamless Interaction (v12)
Full-body framing; head rotation takes over.全身構図。頭部回転が主役に替わる。
Both are single forward passes of the trained checkpoints over held conversations —
no cherry-picked generation, just the model's per-frame belief plotted against what
actually happened.
どちらも学習済みチェックポイントによる単一 forward pass。生成のチェリーピックではなく、
モデルのフレームごとの確信度を実際に起きたことと並べて描画しただけのものである。
A methodological warning about input ablation入力 ablation についての方法論的警告
Our first attribution attempt zeroed input dimensions post-hoc at eval time.
Because the face encoder normalizes across all 61 dims, partial zeroing pushes the
input out of distribution and fabricates attribution: head translation — a
constant per clip — appeared to carry a massive +0.278 AUC drop. Re-training with
the same dims zeroed consistently at train and eval time removes the artifact
(true translation contribution: 0.000) and the face effect itself grows 2.4×, from
+0.039 to +0.094. Post-hoc input zeroing through a normalization layer is not a
valid ablation.
最初の寄与分析では、評価時に入力次元を事後的にゼロ化していた。顔エンコーダは
61 次元全体で正規化するため、部分的なゼロ化は入力を分布外に押し出し、寄与を捏造する:
クリップごとの定数にすぎない頭部並進が +0.278 という巨大な AUC 低下を持つように見えた。
同じ次元を学習時と評価時に一貫してゼロ化して再学習するとこのアーティファクトは消え
(並進の真の寄与: 0.000)、顔の効果自体も +0.039 から +0.094 へと 2.4 倍に拡大した。
正規化層を通した事後的な入力ゼロ化は、有効な ablation ではない。
BibTeX
@article{anonymous2026face,
title = {Making Spoken Dialogue Models See the Face: An Explicit Turn-Taking
Objective Unlocks Visual Turn Cues That Next-Token Audio Prediction Ignores},
author = {Anonymous},
journal = {Under review},
year = {2026}
}